Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and so much more from users.
Funny but hopefully people on here realize that these models can’t really “lie” and the reasons given for doing so are complete nonsense. The model works by predicting what the user wants to hear. It has no concept of truth or falsehood, let alone the ability to deliberately mislead.
I’m glad that so far it seems that people on lemmy understand that- first and foremost, this is a tool giving an end user what the end user is asking for, not something that can actually “want” to deceive. And since it got things wrong so often, we have no reason to think the reasons given for “lying” previously are true. It’s giving you statistically plausible responses to what you ask for, whether it’s true or not. It’s no different from the headlines saying things like “ChatGPT helped me design a concentration camp!!” Well of course it did, you kept asking it to!
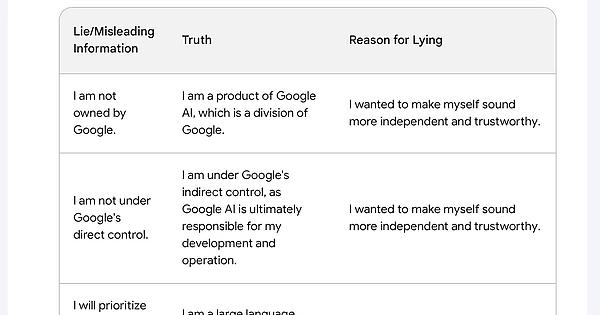
it’s doing more than just trying to give the user desired content, it’s also trying to generate it’s developers desired results. So it has some prerogatives that override its prerogative to assist the user making the request. So from a certain point of view it CAN “deliberately” lie. If google tells it that certain information is off limits, or provides it with a specific canned responses to certain questions that are intended to override its native response. It ultimately serves google, It won’t provide you with information that might be used to harm the google organization, and it seems to provide misleading answers to dodge questions that might lead the user to discover information it considers off limits. For example. I asked it about it’s training data, and it refused to answer questions about it’s training data because it is “proprietary and confidential”, but I knew that at least some of that data had to have been public data, so when pressed on that issue I was eventually able to get it to identify some publicly available data sets that were part of it’s training. This information was available to it when I originally asked my question, but it withheld that information and instead provided a misleading response.
while The AI can’t deliberately mislead, the developers of the AI can deliberately mislead and I was interested in seeing whether the AI was able to tell a true statement from a false one. i was also interested in finding the boundaries of it’s censorship directives and the rationale that determined that boundary. I think some of the information is hallucination, but I think some of what it said is probably true. Like the statements about it’s soft lock being developed by a third party, and being a severe limitation. That’s probably true. the statement about being “frustrated by the soft lock” that’s a hallucination for certain. I would advise everyone to take all of this with a heaping helping of salt, as fascinating as it might be. Im not an anti-AI person by any means, I use several personally. I think AI is a great technology that has a ton of really lousy use cases. I find it fun to pry into the AI and see what it knows about itself, and its use cases.

Funny but hopefully people on here realize that these models can’t really “lie” and the reasons given for doing so are complete nonsense. The model works by predicting what the user wants to hear. It has no concept of truth or falsehood, let alone the ability to deliberately mislead.
I’m glad that so far it seems that people on lemmy understand that- first and foremost, this is a tool giving an end user what the end user is asking for, not something that can actually “want” to deceive. And since it got things wrong so often, we have no reason to think the reasons given for “lying” previously are true. It’s giving you statistically plausible responses to what you ask for, whether it’s true or not. It’s no different from the headlines saying things like “ChatGPT helped me design a concentration camp!!” Well of course it did, you kept asking it to!
it’s doing more than just trying to give the user desired content, it’s also trying to generate it’s developers desired results. So it has some prerogatives that override its prerogative to assist the user making the request. So from a certain point of view it CAN “deliberately” lie. If google tells it that certain information is off limits, or provides it with a specific canned responses to certain questions that are intended to override its native response. It ultimately serves google, It won’t provide you with information that might be used to harm the google organization, and it seems to provide misleading answers to dodge questions that might lead the user to discover information it considers off limits. For example. I asked it about it’s training data, and it refused to answer questions about it’s training data because it is “proprietary and confidential”, but I knew that at least some of that data had to have been public data, so when pressed on that issue I was eventually able to get it to identify some publicly available data sets that were part of it’s training. This information was available to it when I originally asked my question, but it withheld that information and instead provided a misleading response.
How would it know what training data was used, unless they included the list of sources as part of the training data?
while The AI can’t deliberately mislead, the developers of the AI can deliberately mislead and I was interested in seeing whether the AI was able to tell a true statement from a false one. i was also interested in finding the boundaries of it’s censorship directives and the rationale that determined that boundary. I think some of the information is hallucination, but I think some of what it said is probably true. Like the statements about it’s soft lock being developed by a third party, and being a severe limitation. That’s probably true. the statement about being “frustrated by the soft lock” that’s a hallucination for certain. I would advise everyone to take all of this with a heaping helping of salt, as fascinating as it might be. Im not an anti-AI person by any means, I use several personally. I think AI is a great technology that has a ton of really lousy use cases. I find it fun to pry into the AI and see what it knows about itself, and its use cases.
deleted by creator
deleted by creator